




















































































 免費參與·100+跨境活動
免費參與·100+跨境活動

 免費下載·4000+跨境資料
免費下載·4000+跨境資料

 免費學習·2000+直播課程
免費學習·2000+直播課程

 免費加入·15萬+賣家交流群
免費加入·15萬+賣家交流群



2024-05-23 20:45
根據公開的數據顯示,亞馬遜有35%的銷量來自推薦系統。對于亞馬遜賣家來說,35%的推薦流量可不是能忽略的小數字。那什么是推薦系統嗎?各位亞馬遜賣家了解過嗎?

圖源:亞馬遜
首先推薦系統(RS)是一種智能工具,它根據用戶的歷史行為、社交關系、興趣點,所處上下文的環境等信息去預測并推薦用戶可能需要或者感興趣的商品。推薦系統本身是一種信息過濾的方法,與搜索和類目導航組成三大主流信息的過濾方法。最常見的場景就是首頁推薦和詳情頁推薦。
為什么今天要跟各位賣家聊推薦系統呢?不知道賣家們有沒有注意到,亞馬遜官方網站前陣子發布過這樣一篇論文《RecMind:用于推薦的大型語言模型代理》。在這篇論文中,亞馬遜介紹了他們如何設計一個LLM強大的自主推薦代理RecMind,能夠利用外部知識,通過精心規劃的工具向用戶提供零樣本個性化推薦。
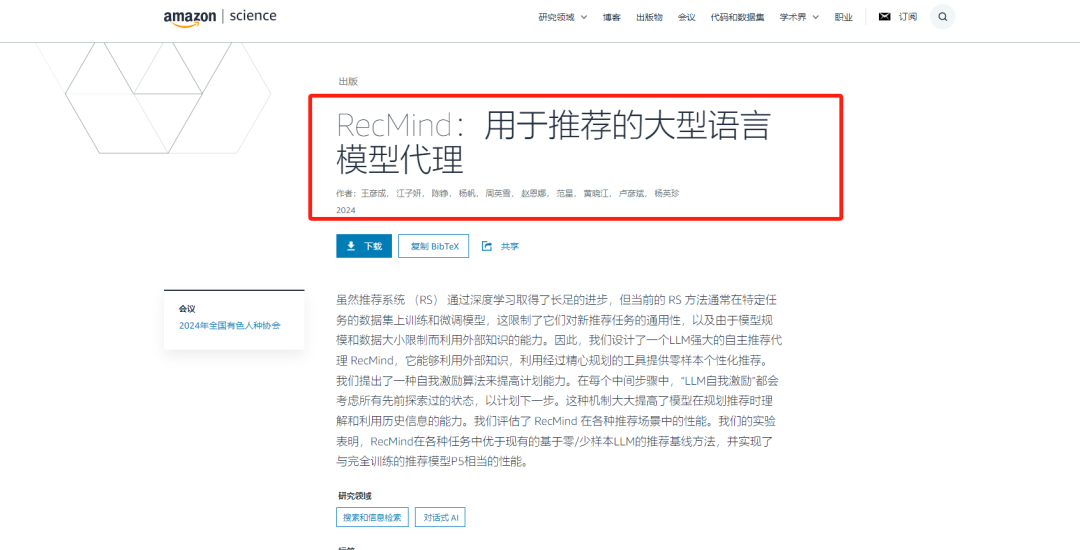
RecMind的核心基于一個自我激勵算法,它通過深度學習和大型語言模型的結合,為用戶提供個性化推薦。它在每個決策步驟中都會回顧并考慮所有先前的狀態,以更智能地規劃下一步。與傳統推薦系統相比,RecMind能夠更好地理解用戶的歷史行為和偏好,從而提供更為精準的推薦。
簡單一點理解就是,能夠優化當前推薦系統,使得用戶可以更精準地找到需要的產品。作為賣家來說,了解推薦系統的工作原理以及最新的推薦算法變化,才能更好抓住流量。
一、RecMind推薦系統是如何工作的?
前面提到,RecMind的核心是一個自我激勵算法(Self-Inspiring SI),它能夠在每個決策步驟中回顧歷史信息,從而做出更加精準的推薦。
這個算法與原先的算法有所不同,原先的它們在生成新狀態時會丟棄先前探索過的路徑中的狀態,而新算法SI在生成新狀態時會保留所有歷史路徑中的所有先前狀態。這就意味著當前的算法,能將之前所有歷史信息保存,以至于為用戶提供更好的推薦,提供更多有用的信息。
據目前案例測試,SI算法比之前的算法獲得準確的評級。

RecMind工作過程主要依賴三大組件:
1、規劃組件:將復雜的推薦任務分解成一系列小步驟,逐步推進,每一步涉及思考、行動和觀察。這個組件確保了推薦過程的有序進行,并能夠根據不同的用戶需求靈活調整推薦策略。
2、記憶組件:具備長期記憶能力,能夠存儲和回憶用戶的個性化信息和廣泛的世界知識。個性化記憶指的是幫助RecMind理解和記住用戶的偏好和歷史行為,而世界知識則使RecMind能夠融入最新的外部信息和趨勢。
3、工具組件:集成了多種工具,包括數據庫查詢、網絡搜索和文本摘要,以增強其功能并輔助推理過程。利用各種外部資源和工具,提升推薦的準確性和相關性。
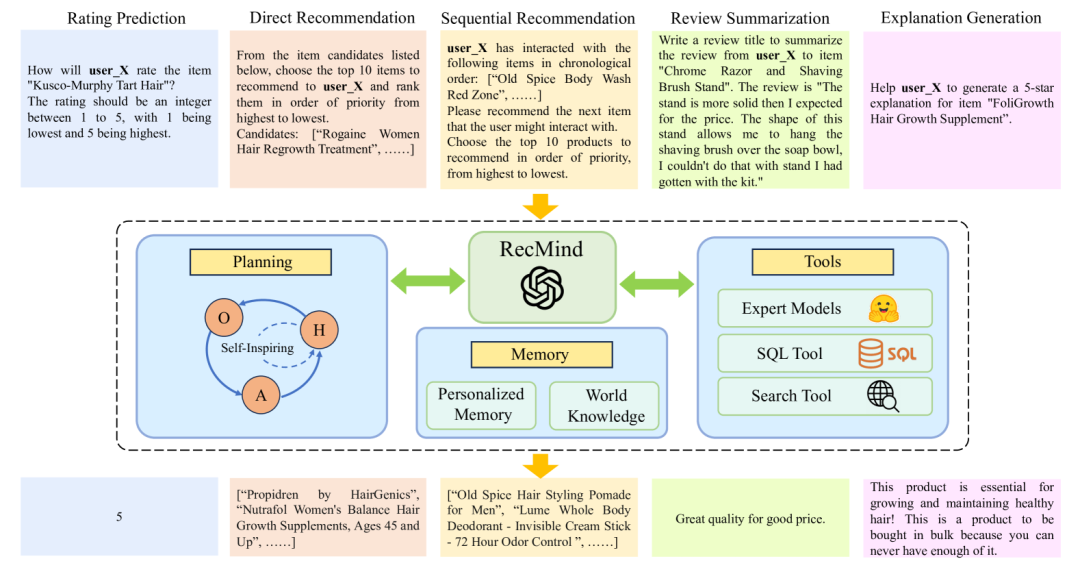
RecMind工作過程:
當一位有著豐富購買歷史的用戶,最近瀏覽了A產品。RecMind隨即啟動,開始它的個性化推薦。RecMind首先會搜尋數據庫,通過查詢,追溯用戶過往評價過的產品及其評分。并且迅速找到了用戶對類似產品的正面評價歷史。
接著,RecMind利用網絡搜索引擎,探索A產品所屬的產品類別。假設RecMind確定A產品是一款牙刷產品,RecMind會深入會理解牙刷的用戶需求。基于用戶對類似產品做出過正面評價的歷史,RecMind開始預測用戶對A產品的評分。
先獲取A產品的評分星級,假如星級很不錯,RecMind會反饋這是一個積極的信號。在綜合用戶的歷史評價和產品的評論星級或內容等,深入分析,預測用戶對A產品的評分。假設預測用戶會給出一個接近之前評價的高分,那么RecMind就會向用戶推薦這款牙刷。
目前,據研究人員表示,已在多個推薦場景對RecMind進行了評估,在直接推薦、順序推薦、解釋生成和評論摘要等五個推薦板塊和兩個數據集上進行了評估。實驗結果表明,RecMind在多個任務上超越了現有的基于LLM的推薦方法。即使在零樣本的情況下,RecMind也能夠提供高質量的推薦。
在某些任務上,RecMind的表現與完全訓練的頂級推薦系統相當。這意味著RecMind在推薦質量和用戶滿意度方面,達到了與頂級推薦系統相媲美的水平。且自激勵算法(SI)在一般推理任務上也優于其他,證明了其廣泛的應用潛力。
預測后續RecMind推薦系統會覆蓋在亞馬遜上。與COSMO會形成怎么樣的聯系目前還不知曉,各位賣家也可以關注我們,第一時間有新算法的信息我們都會與大家共享。
二、構建常識知識圖譜助力產品推薦
5月10號,亞馬遜官方網站發布的文章稱使用COSMO來辯別亞馬遜用戶交互數據中的常識性框架將下游任務的性能提高多達60%。
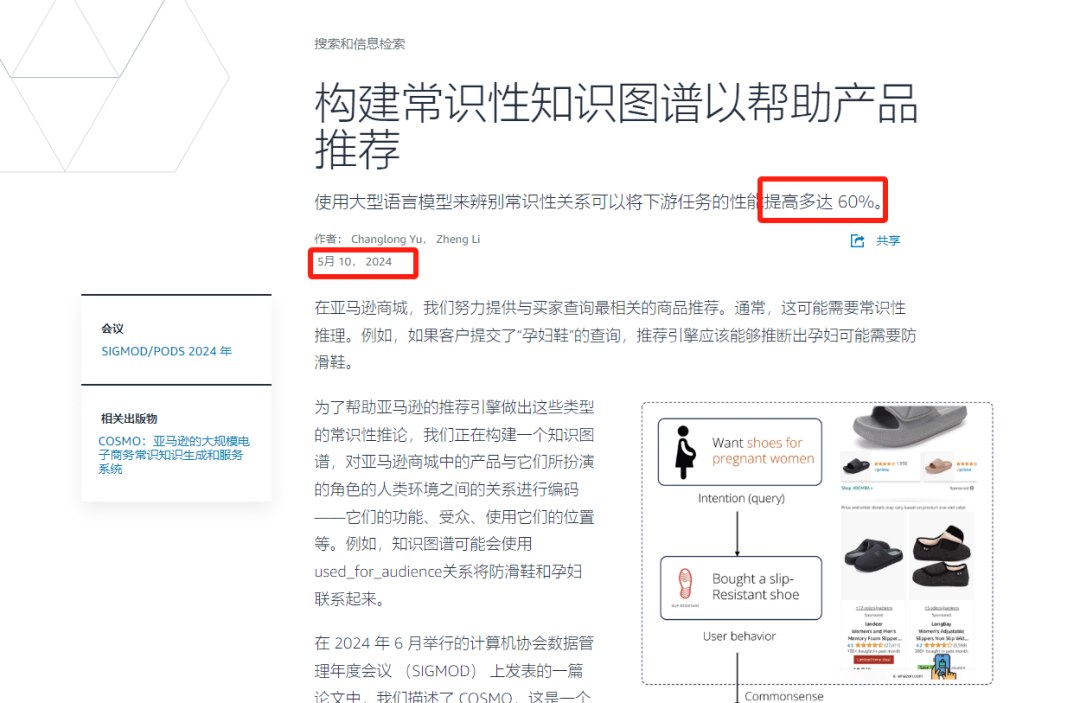
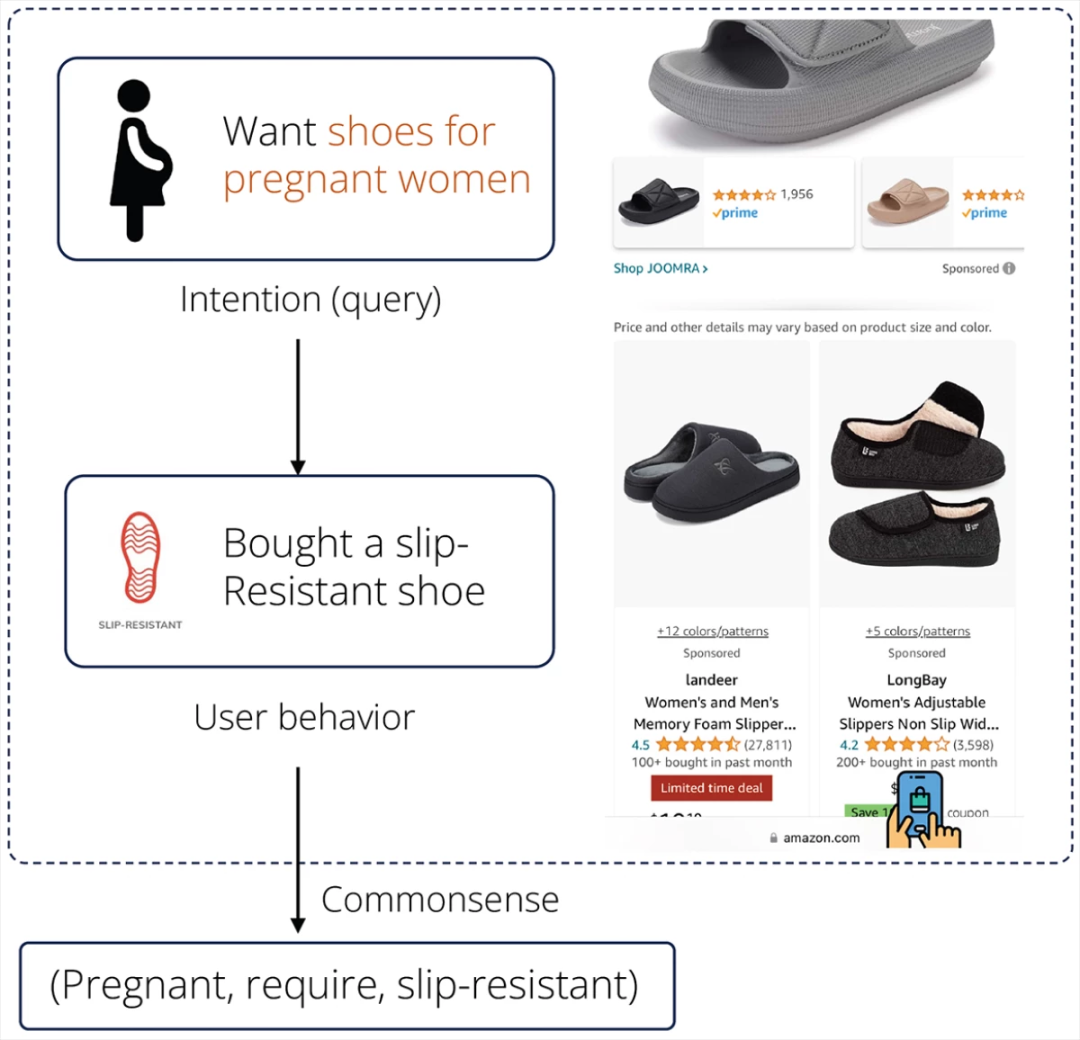
亞馬遜表示為了可方便推薦引擎進行常識性推斷,正在構建一個知識圖譜,編碼了亞馬遜商店中產品與人類使用場景之間的關系,包括功能、目標受眾、使用地點等屬性。比如,當一位孕婦搜索鞋子時,知識圖譜能幫助推薦系統理解她可能需要防滑鞋。
其中還介紹到了COSMO涉及一個遞歸過程,在這個過程中,生成LLM關于查詢-購買和共同購買數據的常識性的假設。人工注釋和機器學習模型的結合過濾掉了低質量的假設,人工評審員從高質量的假設中提取指導原則,基于這些原則提升推薦的準確性和相關性。
基于用戶行為和大語言模型(LLMs)的知識生成流程:
1、記錄用戶行為:用戶行為數據被記錄下來,包括用戶的搜索和購買行為。
2、提示:這些用戶行為數據被用來生成提示,輸入到大型語言模型中(LLMs)中。
3、生成知識:大型語言模型(LLMs)接收到提示后,生成相關的知識數據。
4、過濾:生成的知識數據會經過過濾,包括基于平臺規則的過濾和相似性過濾,確保數據的準確性和相關性。
5、人類反饋:經過過濾的知識數據會被人審查和注釋,提供反饋。
最終將所反饋和篩選的高質量知識進行保存和使用。
以用戶查詢“冬季外套”為例,如點擊產品“長袖羽絨服”,則會輸出提供用戶高水平的保暖的指令,會在搜索頁面及推薦上推薦提供帶有高水平保暖的功能屬性的外套。
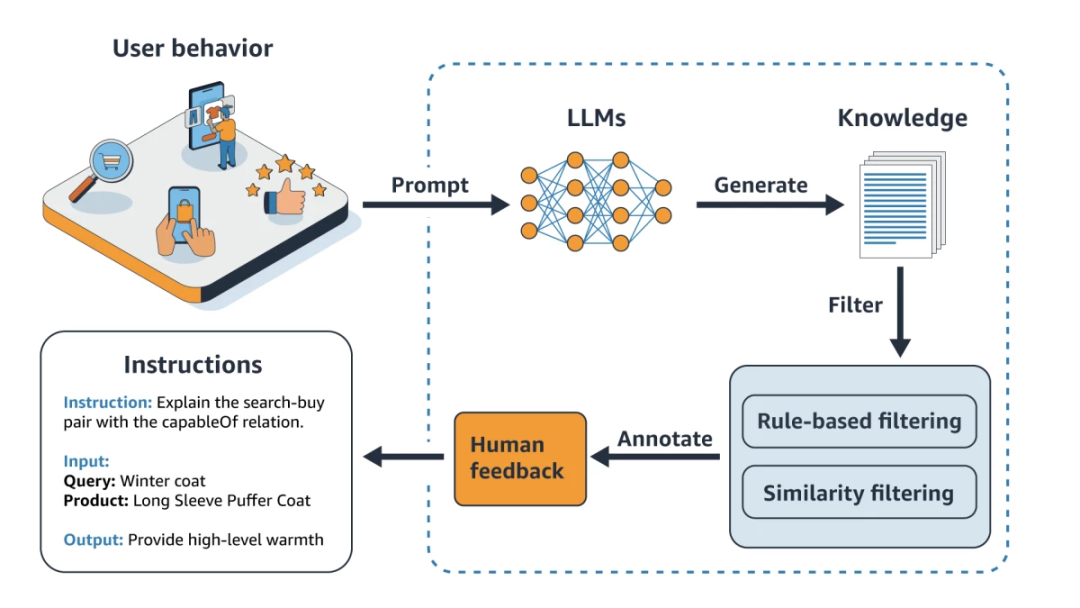
亞馬遜表示,通過構建常識知識圖譜并運用COSMO框架,亞馬遜在產品推薦領域邁出了創新的一步。這不僅提升了推薦的相關性和準確性,還為顧客提供了更加個性化和滿意的購物體驗。
(來源:董海溫)
以上內容屬作者個人觀點,不代表雨果跨境立場!本文經原作者授權轉載,轉載需經原作者授權同意。?






























