





















































































 免費參與·100+跨境活動
免費參與·100+跨境活動 
 免費下載·4000+跨境資料
免費下載·4000+跨境資料 
 免費學習·2000+直播課程
免費學習·2000+直播課程 
 免費加入·15萬+賣家交流群
免費加入·15萬+賣家交流群 


2024-03-11 10:21
好消息是:本月沒有核心算法更新。另一個不好不壞的消息:本期月報的內容依然很充實。谷歌自然是不會因為我們本月只有 18 個工作日而停止進取工作的步伐,何況今年的2月有29天,似乎是比去年同期還多一個努力的工作日呢!話不多說,本期的月報同樣也會為你帶來眾多有關 Google 新動態、技術 SEO、AI 和 SEO、行業人士調研、經驗分享、表情包等等資訊。
1.Core Web Vitals 指標變更:INP 將取代 FID
眾所周知,Core Web Vitals 作為評估網頁性能以及體現網站用戶體驗的一項技術 SEO 指標,自 2020 年上線以來一直都備受站長關注。
而在 2023 年 5 月,為便于更準確地衡量用戶的互動情形,官方再次引入了 INP (Interaction to Next Paint, 下個繪制互動時間)指標,并預計在 2024年3月12日取代原有的 FID (First Input Delay, 首次輸入延遲)指標。目前網站內各個頁面的 FID 分數均能在 Google Search Console 報表中看到。
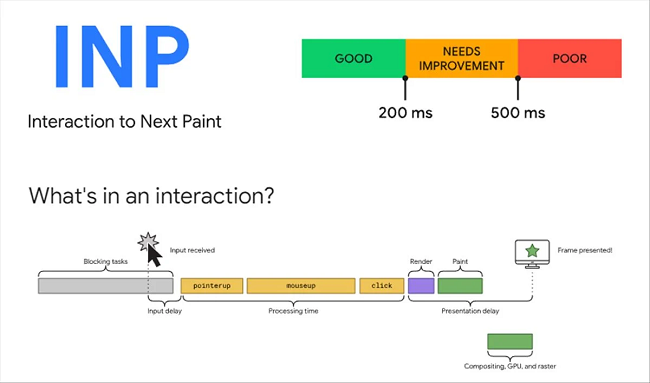
圖片來源:https://www.searchenginejournal.com/
但該怎么理解 FID 這一指標?而谷歌為什么會替換呢?根據官方的定義,INP 用來觀察網頁加載之后,用戶和網頁的互動時間。用戶在頁面中一切的點擊或按鍵輸入行為都會計入為用戶與網站的互動。而一連串行為中,最長的互動時間則為 INP 的數據。
與 FID 最大的不同在于,FID 指計算用戶在網頁首次的互動時間,因此 INP 的數據能夠更客觀地評估網頁的互動是否存在過多的延誤。從這里也能看出,INP 和 FID 其實都會統計前端 JavaScript 的響應時間。因此,有需要優化 INP 指標的伙伴,也可以參考 FID 的改善方式去優化這一指標。
信息源:https://www.seroundtable.com/inp-google-core-web-vitals-march12-36819.html
如果執行 INP 優化這項工作的過程中,還需要其它工具協作,也可以參考這篇文章噢!
https://www.searchenginejournal.com/inp-tools/507355/
2.Google:Core Web Vitals 并非直接的排名因素
新的一年我們依舊關心谷歌會不會推廣新的排名因素。但可能在谷歌看來,推翻你的認知會更容易一些。
近日(2月5日),谷歌聯絡處的代表 Danny Sullivan 在 X 上回應網友的提問時,表示:谷歌在決定網頁排名時會考慮很多因素,而不僅僅是頁面體驗或核心網絡指標這類因素。他強調即便是這些因素,也不一定直接影響網頁的排名。換句話說,谷歌的排名算法非常復雜,不會只依賴某個單一的指標。
到底 Core Web Vitals 是不是確切的、谷歌納入衡量的排名因素呢?這個話題 Search Engine Journal 其實在去年 12 月的時候,有發布一篇文章:Are Core Web Vitals A Ranking Factor? 整合谷歌官方人員的觀點,探討過。甚至在搜索 Core Web Vitals 是否為排名因素這一問題時,能夠看到行業知名人士 Backlinco 的文章里會把其當成是排名因素。

圖片來源:https://www.searchenginejournal.com/
能確定的是,這個指標在谷歌大力推廣 Helpful Content 的過程中,能夠更直觀地幫助評估頁面的瀏覽體驗夠不夠用戶友好。雖然在看完一系列的整合后會感受到谷歌依然會比較謎語人,但正如官方文檔的定義或者說 Danny 的解釋,CWV 不是唯一因素,SEO 的工作始終要關注整體效應。
信息源:
https://www.seroundtable.com/google-core-web-vitals-search-ranking-factor-36834.html
3.濃縮再濃縮!新版 《谷歌 SEO 入門指南》 發布了
2月2日,新版《谷歌 SEO 入門指南》如期而至。本次更新的版本刪減了比較多的內容,變得更加簡潔易讀,即便是對SEO一無所知的人也能快速獲取關鍵信息。而對于已經有一定基礎的SEO專業人士來說,這份指南可能內容過于基礎,但對于初學者來說,它提供了一個很好的起點,幫助他們了解SEO的基礎知識和重要概念。
除了2008年的首版外,實際上谷歌對這份SEO入門指南進行了幾次更新,分別在2010年和2017年,目前的改動主要集中在:
刪減了這些內容:
SEO 術語:相關術語會直接透過語境便于讀者理解
結構化數據:這部分內容谷歌認為屬于進階的話題
移動端友好:因為目前大部分新站點都會注重移動端的優化
分析站點性能:屬于 SEO 比較后期的工作,不太符合目前初學指南的定位
新增了這些內容:
為什么這樣做:用于幫助讀者更好地理解SEO的重要性和實施的動機
關于重復內容:添加了關于什么是重復內容以及如何解決重復內容問題的解釋,并新增了一個小節簡要介紹視頻內容的 SEO 優化
SEO 理論和想法:新增了關于常見SEO理論和想法的部分,指出了人們不應該過分關注的領域。同時,也新增了有關看到SEO效果可能需要多長時間的討論
精簡壓縮了這些內容:
圖片內容:特別強調alt文本的重要性
鏈接部分:強調了鏈接對用戶和搜索引擎的作用
網站結構部分:刪除了如導航部分,404錯誤頁面的處理,以及面包屑設置的具體內容,因為這些內容更偏向于進階主題
能看出來,此次改動對剛開始接觸SEO的人來說,整份文檔在降低了閱讀難度的同時,保留了對 SEO 至關重要的信息和建議。
信息源:
https://www.seroundtable.com/google-revised-seo-starter-guide-36831.html
4.網站的 404 死鏈還沒有徹底清除,直接在 GSC 上點擊驗證修復會有問題嗎?
處理站點的 404 錯誤是 SEOer 的日常工作事項。但對新手來說,404 錯誤代碼似乎又是一個容易讓人迷惑的概念。于是谷歌的 John Mueller 在本月也回應了網友處理 404 錯誤的問題。
404狀態代碼表示請求的網頁不存在,這可能是由于網頁已刪除或URL地址錯誤導致的。而不是指Google在頁面上發現了需要修復的錯誤。在GSC中,驗證修復404錯誤的過程是為了跟蹤和管理網站上的丟失頁面。
理論上,如果已知一個404狀態是永久性的且頁面永遠不會返回,那么更正確的響應應該是顯示410狀態碼。但Google幾乎將404和410響應碼等同對待,410響應會使頁面從Google的搜索索引中稍微快一點被移除,但最終結果是相同的。
針對站點內部或外部鏈接失效導致的 404 錯誤,John Mueller 給出了以下建議:
如果是內部404錯誤:提交驗證修復可以幫助您跟蹤和管理網站上的丟失頁面,并告訴Google哪些頁面已經被修復。
如果是外部404錯誤,通常不需要追求修復,除非鏈接來自于合法的網站并且對用戶體驗產生了負面影響。
有的 SEO 專家也會建議使用 301 重定向操作,將錯誤的 URL 導流到正確的 URL 來修復入站鏈接。總的來說,“驗證修復”功能的目的是幫助站長跟蹤修復的效果,以確保Google也看到了這些更改。而處理外部鏈接導致的404錯誤時,需要權衡修復這些鏈接的投入產出比。
信息源:
https://www.searchenginejournal.com/google-on-404-errors-and-search-console-validation-fix/508310/
5.提交 Sitemap 需要注意這一點,避免 Google 無法正常爬取
如果你的 XML 站點地圖文件的命名中有帶連字符,并且連字符后緊跟2個以上的數字時,可能會觸發 GSC 的“無法獲取”錯誤。這個 bug 是由 Screaming Frog 的團隊首次發現并發布到 X 上的。
舉個例子:
如果你的站點地圖文件名是 /sitemap-10.xml,它會觸發“無法獲取”錯誤。
但使用 /sitemap10.xml 作為文件名時,即便是同一個文件,就不會觸發任何錯誤。
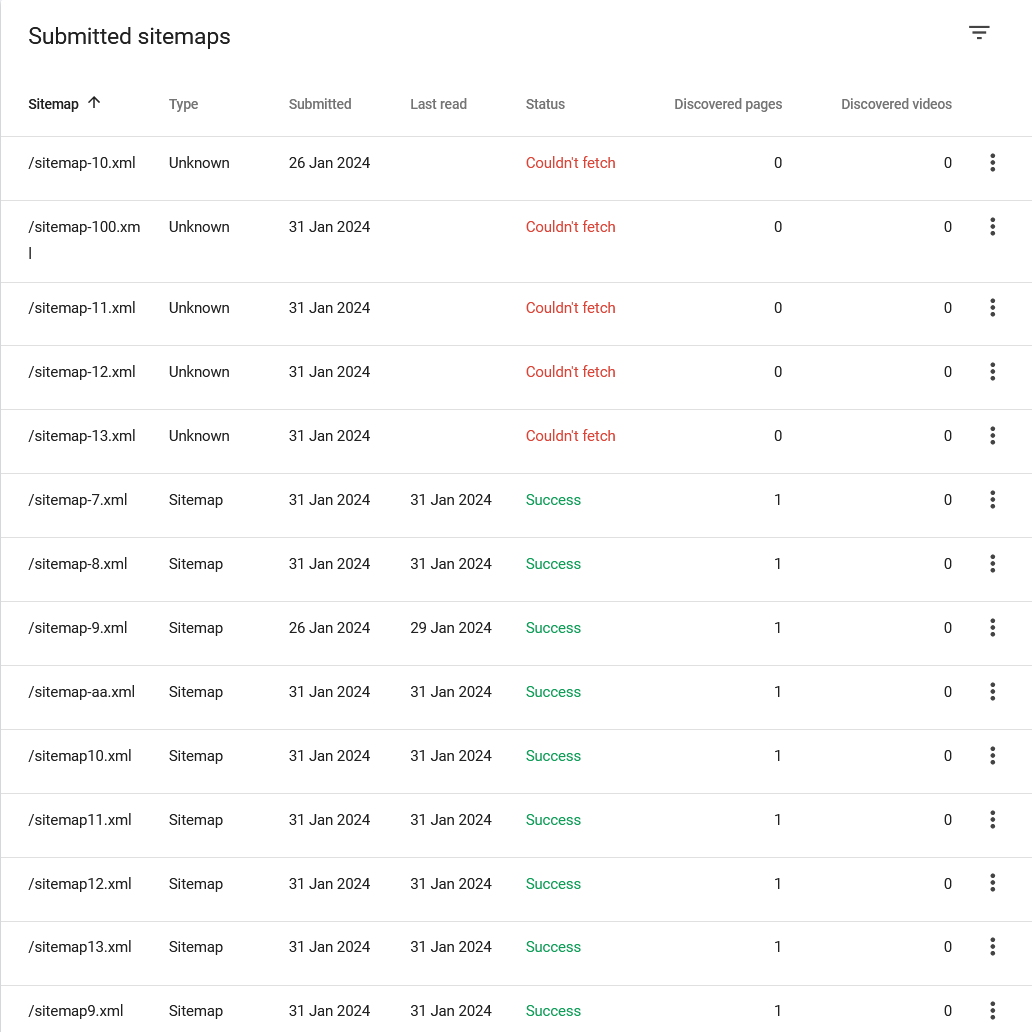
Screaming Frog 也在多個站點中測試提交站點地圖,但還是得到同樣的結果,谷歌對此問題尚未作出回應。
信息源:
https://www.seroundtable.com/google-sitemaps-error-with-hyphenated-file-names-36829.html
6.要如何應對 Reddit 更頻繁地出現在 SERP ,搶占排名呢?
本月備受矚目的信息除了 Sora 之外,還有谷歌與 Reddit 達成了人工智能培訓協議,以便于訓練和增強自家的 AI 模型。但就算谷歌還沒和 Reddit 正式達成合作,不少網站運營人員可能也觀察到 Reddit 甚至各種大型的平臺在 Google 的排名優勢越發突出,可能會對不少小型獨立站點的可見性構成挑戰,排名空間遭到擠壓。
本月,主營業務為家居空氣凈化器的獨立站 HouseFresh 發布了文章:Google is killing independent sites,而讓事情得以發酵,獲得大家、甚至谷歌官方關注的契機在于,同樣的頁面標題,在內容原創的情況下,搜索結果頁中 Reddit 帖子的排名直接超越了這個獨立站。而盡管 Reddit 的帖子也有鏈接到原文章,但就結果來看,可謂是無濟于事。這一現象引發了關于大型網站與小型網站在搜索排名上的競爭不平等的討論。
而援引消息的 Search Engine Land 在本月也有發布另一篇文章,通過擺數據的方式分析 Reddit 在 Google SERP 上是否存在過度展示,導致搜索結果多樣性削弱的問題。文章的分析作者 Glen Allsopp 通過分析10,000個關鍵詞短語,發現 Discussions and forums 的搜索樣式出現了77%的時間,其中 Reddit 幾乎占據了Google討論和論壇SERP功能預留位置的三分之二。這一觀察也引起了 Reddit 的注意,他們回應:分析報告存在缺陷且具有誤導性,并強調展示的 Reddit 帖子并非全都包含網盟的 affiliate 鏈接。
總的來說,盡管大型網站和小型獨立網站之間的競爭不平衡的現象確實存在,但小型獨立站點依然可通過專注于創造高質量的原創內容、建立自己的社區鼓勵用戶參與,和靈活調整SEO策略找尋不被大型平臺主導的關鍵詞(也就是避開:用戶會自發在末尾加 reddit 的關鍵詞),最終仍有機會在搜索引擎中取得好的排名和可見性。
信息源:
https://searchengineland.com/reddit-dominates-google-search-discussions-forums-437501
https://searchengineland.com/article-complaining-about-being-outranked-on-google-being-outranked-by-reddit-437736
https://www.seroundtable.com/google-reddit-content-deal-36944.html
7.不想讓站點內容被用于 Google 的 AI 訓練?更改 Google-Extended 網絡爬蟲文檔就能實現!
本月9號,Google 更新了其 Google-Extended 網絡爬蟲用戶代理文檔。主要更新了相關的 AI 產品命名,并列明了爬取對搜索的影響。另外,不想讓站點內容參與 AI 訓練的用戶,現在有了更多的控制權,可以決定自己的網站內容是否被用于 Google 的AI訓練,而且這一選擇不會影響其在 Google 搜索結果中的表現或排名。這為站長提供了更大的靈活性,同時也要求站長需要對如何管理自己的內容和其在AI技術中的應用有更深入的了解。
信息源:
https://www.searchenginejournal.com/google-clarifies-the-google-extended-crawler-documentation/507645/
8.算法更新蓄力中:2月7號-8號流量波動明顯
距離上一次未經證實的算法更新(1月23日-24日)不到兩周,本月主流的 SEO 檢測工具再次觀察到排名情況有劇烈波動。據 SearchRoundTable 的社區論壇討論,有的網站流量在這期間正常增長,也有的則經歷了流量或關鍵詞排名下滑。如果在這段時間內,有站長發現了不尋常的流量波動,很可能也是算法導致的,建議及時調整自己的 SEO 策略噢。
信息源:
https://www.seroundtable.com/google-algorithm-update-36862.html
9.新的 SERP 樣式:提供購物功能相關的菜單
Google正在測試一個專門針對搜索結果中購物功能的菜單。這個新菜單將添加并應用到購物相關的搜索結果中。用戶在點擊菜單按鈕周,會展示以下子區域的鏈接:購物首頁、訂單、購物設置和購物幫助。這一變化能夠讓用戶的購物體驗更加集中和便捷。
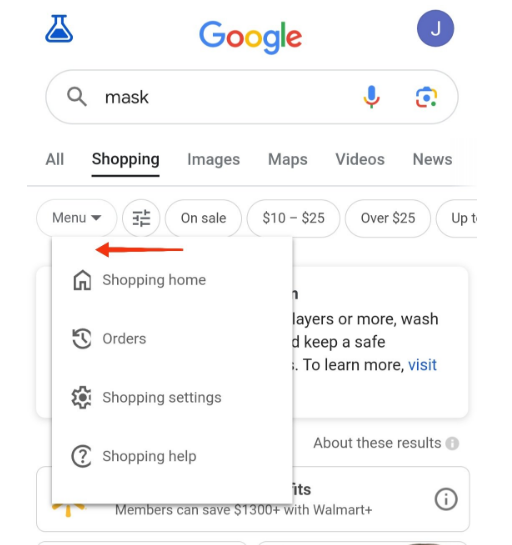
同樣,這也意味著Google搜索正變得更加偏向于電子商務和購物。從事電商相關的獨立站運營人員,可以嘗試:
優化產品頁面和購物相關內容,確保它們符合 Google 的搜索和購物功能標準。
了解 Google 購物特性的新變化,利用這些特性提高產品在 Google 搜索結果中的可見性。
考慮在內容策略中加入更多與購物相關的元素,比如詳細的產品描述、用戶評價以及優惠信息,以吸引 Google購 物搜索的用戶。
信息源:
https://www.seroundtable.com/google-search-testing-shopping-menu-36820.html
10.Canonical 鏈接屬性相關文檔更新,及時檢查保證站點鏈接符合規范
本月要關注的 SEO 技術規范還包括了 canonical 注釋。2月15日,Google 更新了其規范鏈接(canonical link)文檔中關于使用rel=canonical鏈接注釋的部分,明確指出帶有特定屬性的rel=canonical注釋不會視為標準化的網站鏈接。
各位站長看到這則信息之后也無需迷茫,這一更新意味著需要檢查和更新網站中的規范鏈接注釋,確保它們按照Google的最新指導方針進行配置。具體建議如下:
核對現有的規范鏈接注釋:確保不要在用于規范化目的的rel="canonical"鏈接上錯誤地使用hreflang、lang、media和type屬性。
正確使用備選版本鏈接:對于指定頁面的語言和國家備選版本,確保使用link rel="alternate" hreflang注釋,而非錯誤地將這些屬性與rel="canonical"混用。
遵循RFC 6596標準:Google支持按照RFC 6596標準描述的rel canonical鏈接注釋,因此確保你的規范鏈接實施遵循這一標準。
通過遵循這些規范,及時與技術人員溝通,調整站點可能存在問題,幫助確保網站在Google搜索中的表現更加準確和有效。
信息源:
https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls#use-rel=canonical-link-annotations
11.電商結構化數據樣式更新:相似的產品變體可以標記屬性了
Google 最近宣布支持產品變體結構化數據,通過新增的三個屬性:hasVariant、variesBy和productGroupID,來處理電商網站列出產品變體(類似同款不同色的產品)的大部分方式,意在讓搜索結果展示效果更直觀準確,改善用戶體驗。
而運營電商獨立站的站長則需要更新網站上的結構化數據,以確保產品變體正確地被Google識別和索引。具體的操作建議可以在信息源的鏈接中查閱。
信息源:
https://www.seroundtable.com/google-product-variant-structured-data-36924.html
12.需注意:AI 生成的圖像需保留圖像元數據
Google 為商家中心(Google Merchant Center)使用AI生成的圖像發布了新政策。簡而言之,你需要確保這些圖像的元數據標記為使用AI生成,避免潛在的問題或處罰。
Google 要求在商家中心使用AI生成的圖像時,保留指示圖像是使用生成性AI創建的任何元數據標簽。為此,官方文檔還特別提到:不要移除諸如 trainedAlgorithmicMedia 這樣的嵌入式元數據標簽。所有AI生成的圖像必須包含 IPTC DigitalSourceType trainedAlgorithmicMedia 標簽。谷歌還提供了關于IPTC照片元數據的更多學習資源。
此外,對于計劃在文章頭部或其他位置使用AI生成的圖像的內容運營人員來說,盡管谷歌目前尚未為文章和AI圖像制定標準程序,但你可能也可以考慮給這些圖像標上某種標簽,表明它們是由AI生成的。這樣做不僅有助于透明度,也可能對未來可能出臺的相關標準做好準備。
信息源:
https://www.seroundtable.com/google-merchant-center-requires-labels-ai-images-36922.html
13.John Mueller 發話:濫用收錄 Indexing API 的網站有被認為垃圾站點的嫌疑
Google 提醒網站管理員,濫用 Google Indexing API 這一行徑通常容易讓站點與垃圾站或低質量網站掛鉤。John Mueller 強調,Google Indexing API 應僅用于工作職位發布和實時直播內容,對于其他用途,Google 官方不支持且表示這種做法不會有效。
盡管有人嘗試將其用于其他目的,并稱其可以快速索引內容,但這些內容通常會在短時間內從索引中消失。Mueller 表示,雖然看到有人熱衷于嘗試使用該 API 做更多事情是件好事,但大多數這類嘗試都是為了 spam 或上線大量的低質量內容,因此這種做法是不被支持的,還可能影響網站的信譽。
信息源:
https://www.seroundtable.com/google-indexing-api-abuse-spammy-low-quality-36919.html
14.Google:AI 有幫我們更好地鑒別虛假的評論內容
Google 在2月13日發布博文表示,利用 AI 技術,Google 的算法現在可以更有效地識別可疑、虛假的線上評論,例如:能夠檢測在不同商家頁面上復制的相同評論,或評分的異常波動。這一進展對于保護 Google Maps 和 Google 搜索上的本地商家免受可能破壞其聲譽的欺詐性評論至關重要。數據表明,Google 在2023年阻止了超過1.7億條假評論。這一進步標志著與前一年相比,準確性提高了45%。
因此,站長在維護網站的評論內容時,建議落實這些措施來維護網站的聲譽:
專注于真實性:鼓勵真實的客戶反饋,避免使用人為手段提高評分。
監控和參與:定期檢查商家評論,尋找任何可疑活動,并通過回應正面和負面評論積極與用戶互動。
信息源:
https://www.searchenginejournal.com/google-uses-ai-to-detect-fake-online-reviews-faster/508093/
1.多語種站點運營:挑戰和應對方式
SEO 這一行,有一個常見的情況,站長即便不是精通某個小語種的專家,項目的站點卻有多語言、跨地區運營的需求。本期推薦閱讀的干貨是來自 Search Engine Journal 的霓虹地區編輯 Motoko Hunt 在本月發表的文章,過往她也針對 Local SEO 領域,在網站上發布過不少有洞見力的文章。
從文章中,你會了解到:管理多語言和多國家網站的SEO面臨獨特挑戰,包括處理重復內容、不同國家站點的搜索結果顯示問題、以及各個市場之間的SEO流程、技能和重點區域的差異。而文章將會圍繞她在團隊管理和協調、代理商合作事項上的情形,去解決并克服溝通障礙(如語言和時區差異)、人員之間不同的SEO技能和知識水平、項目之間不同的預算分配、以及在內部團隊和代理商之間存在的不同SEO結構相關的問題。
原文:
https://www.searchenginejournal.com/unique-challenges-multilingual-multinational-websites/503481/
2.大品牌是否真的在 Google 中更有優勢?這種形勢會發生變化嗎?Google 會干預嗎?
在近期的資訊中,不乏報導 Reddit 擠掉獨立站排名的現象,也引起了業界不少的議論。SEO 的專家 Marie Haynes 也在最近發布了文章,探討了大品牌在谷歌搜索結果中的主導地位以及未來這一現象可能發生變化的原因,給大家打打雞血,加油鼓勁。
她提出,盡管大品牌因為鏈接(可能也可以理解為鏈接攢下的權重)而占據優勢,但谷歌對有用內容的獎勵機制正在變化。谷歌的AI系統,尤其是最新的Gemini 1.5模型,正在提高識別和獎勵真正有幫助內容的能力。這意味著,即使是小型網站,只要內容真正有用、獨特且展示了真實經驗,也有機會獲得更好的排名。
原文:
https://www.mariehaynes.com/why-big-brands-dominate-google-and-how-this-is-soon-likely-to-change/
3.全世界的內容都一樣爛時,谷歌會給用戶展示什么樣的結果?
接觸 SEO 久了之后,你是否偶爾會質疑:其實谷歌壓根都分辨不出內容質量的優劣,網站之間的排名競爭不過是玄學呢?
如果你會因為谷歌算法、排名機制對站點帶來的負面影響,而感到迷茫、憤世嫉俗時,不妨閱讀這篇文章,換換心情。文章探討了為什么一些網站的內容沒有在谷歌搜索中獲得好的排名,可能的原因是這些內容質量其實并不高。作者Danny Goodwin 指出,很多人認為他們創造的內容是高質量的,但實際上這些內容在最好的情況下也只能算是次優的。
他提出,真正優秀的內容是非常罕見的,不論是AI生成的還是人類創造的,網絡上充斥著大量的普通內容。此外,文章也同樣提及了大品牌在搜索結果中的主導地位,以及谷歌如何處理這個問題。
最后,別忘記,SEO是一個長期的游戲,需要不斷地學習和調整策略,同樣地,建立品牌聲譽是一個長期的過程,需要耐心和持續的努力。
原文:
https://searchengineland.com/google-rank-search-content-sucks-437752
4.有什么方法能讓 AI 內容變得更像人寫的
不可否認,像 ChatGPT 這一類型的生成式 AI 大大解放了內容的生產效率,但生成式 AI 同樣也衍生了很多與內容質量有關的問題,包括內容準確性不佳以及內容重復這些常見現象。
所幸,隨著我們對 AI 指令的理解加深,是有辦法通過提供更詳細的提示詞指令來精細化 AI 生成的內容的。 這里推薦的文章提供了如何使用 ChatGPT 來創造聽起來更像人類的長篇內容的策略。作者強調了給AI設置詳細的提示以產生更具吸引力、更富有情感和針對特定受眾的文章的重要性。這包括明確內容的主題、想要的情感和語調、目標受眾、具體細節、例子和類比,甚至是期望的字數范圍。當然啦,最后的內容還是要人工復查,必要時也可以增加人性化的創意元素,保證最終的成稿能夠做到既有深度,又能引起共鳴。
原文:
https://searchengineland.com/how-to-make-your-ai-generated-content-sound-more-human-437854
5.為什么不建議你阻止 GPT 的 bots 爬取網站內容
有的站長可能會擔心自己站點的內容被用于 AI 訓練之后,會產生負面影響。除了 Google 官方提供的如何不讓內容被用于 AI 訓練相關教程外,不妨看看另一個視角,AI 爬取網站內容,有哪些好處呢?
這篇文章討論了為什么不應該阻止 GPTBot 抓取你的網站,并提出了三個主要的理由。
首先,每周有1億人使用 ChatGPT,不允許 GPTBot 抓取你的網站意味著錯過了最大化品牌可見性的機會。
其次,隨著 AI 在營銷領域的變革,生成式引擎優化 (GEO) 正成為 SEO 的一個子領域,不參與其中將導致錯過重要的市場機會。
最后,OpenAI 承諾最小化傷害,并在其平臺上明確表示將盡量減少傷害,有政策尊重版權和知識產權,GPTBot 也會過濾掉違反其政策的來源。
或許,也可以抱著做慈善的心態,讓 AI 的訓練數據源能夠保持一定質量,為提高 AI 信息的準確性貢獻力量?
原文:
https://searchengineland.com/why-not-block-gptbot-crawling-your-site-437902
以上就是我們本期Google SEO月報的全部內容, 希望大家喜歡! 如果對本期內容有疑問, 可以在評論區留言告訴我們。
(來源:Kenyth)
以上內容屬作者個人觀點,不代表雨果跨境立場!本文經原作者授權轉載,轉載需經原作者授權同意。?
 收錄于以下專欄
收錄于以下專欄
































