





















































































 免費參與·100+跨境活動
免費參與·100+跨境活動 
 免費下載·4000+跨境資料
免費下載·4000+跨境資料 
 免費學習·2000+直播課程
免費學習·2000+直播課程 
 免費加入·15萬+賣家交流群
免費加入·15萬+賣家交流群 


2022-08-16 16:50

圖片來源:Riven@跨境男孩
眼中腳下路,心中要有宏圖。大家好,我是Riven@跨境男孩。這里主要分享獨立站、SEO相關知識。相互交流,共同成長。
本文共計4000余字,預計閱讀3min。
URL 參數會創建重復的內容、浪費抓取預算并稀釋排名信號等。給大家分享幾個避免 URL 參數影響 SEO 的方法。
雖然參數受到開發人員和分析愛好者的喜愛,但它們對SEO確實不太友好。URL的參數組合可以從相同的內容中創建數成百上千個 URL 變體。
最關鍵的是我們不能簡單的不使用URL參數。因為參數在網站的用戶體驗中發揮著重要作用。因此,我們需要了解如何以對 SEO 友好的方式處理它們。
本文分享內容主要有:

圖片來源:Riven@跨境男孩
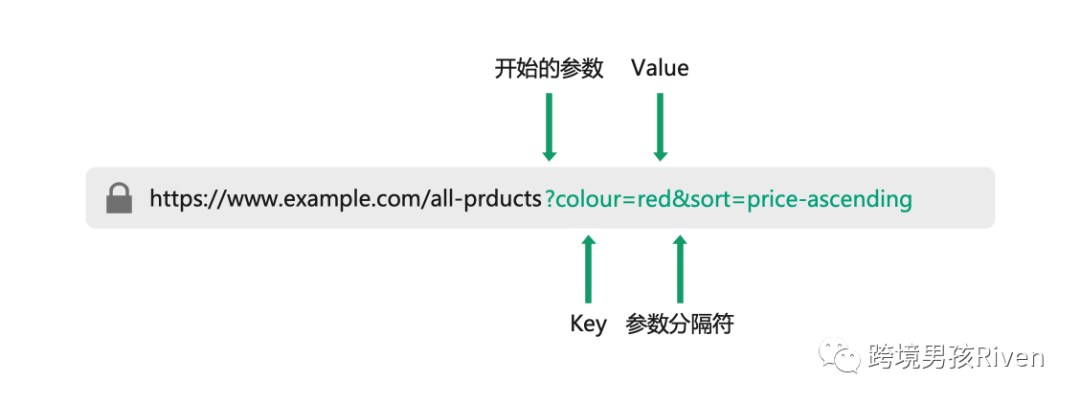
圖片來源:Riven@跨境男孩
URL參數也稱為查詢字符串或 URL 變量,參數是 URL 中跟在問號后面的那部分。它們由一個鍵(Key)和一個值(Value)組成,用等號(=)分隔。可以使用 & 符號將多個參數添加到單個URL頁面。
1)跟蹤:如 ?utm_medium=social、?sessionid=123 或 ?affiliateid=abc
2)重新排序:如 ?sort=lowest-price、?order=highest-rated 或 ?so=newest
3)過濾:如 ?type=widget、color=blue 或 ?price-range=20-50
4)識別:如 ?product=small-blue-widget、categoryid=124 或 itemid=24AU
5)分頁:如 ?page=2、?p=2 或 viewItems=10-30
6)搜索:如 ?query=users-query、?q=users-query 或 ?search=drop-down-option
7)翻譯:如 ?lang=fr、?language=de
通常情況下,URL 參數不會對頁面內容進行重大更改。重新排序的頁面版本通常與原始版本沒有太大區別。帶有跟蹤標記或會話 ID 的網頁網址與原始網頁網址相同。
例如,以下Shopify的站點URL 都將返回熱銷產品列表。
靜態網址:https://www.jcojewellery.com/collections/best-seller
重新排序參數:https://www.jcojewellery.com/collections/best-seller?sort=price-ascending
識別參數:https://www.jcojewellery.com/collections/best-seller?pf_t_material=925+Silverhttps://www.jcojewellery.com/collections/best-seller?pf_t_colour=metal%3Agold
組合參數:https://www.jcojewellery.com/collections/best-seller?sort=created-descending&pf_p_price=25.01047628%3A62.66253870
跟蹤參數:https://www.jcojewellery.com/collections/best-seller?sessionID=32764
搜索參數:https://www.jcojewellery.com/search?q=925+Silver
這實際上是相同內容的相當多的 URL。現在想象一下你網站上的每個類別、顏色、材料、價格區間等。
搜索引擎將每個基于參數的 動態URL 視為一個新頁面。因此,他們會看到同一頁面的多個變體。所有都提供重復的內容,并且都針對相同的關鍵字詞組或語義主題。
這種重復頁面不太可能被完全過濾,它會導致關鍵字蠶食,并且可能會降低 Google 對你的整體網站質量的看法,因為這些額外的 URL 不會增加實際價值。
爬取冗余參數頁面會消耗爬取預算,降低你的網站索引 SEO 相關頁面的能力并增加服務器負載。
Google搜索中心文檔中有提及到這一點:

圖片來源:Google
過于復雜的 URL,尤其是那些包含多個參數的 URL,可能會創建大量不必要的 URL,這些 URL 指向您網站上相同或相似的內容,從而給爬蟲帶來問題。因此,Googlebot 可能會消耗比必要更多的帶寬,或者可能無法完全索引您網站上的所有內容。
如果你有相同頁面內容的多個排列組合,則社交分享鏈接可能會出現不同的版本。
這會稀釋你的URL排名信號。當URL參數混淆爬蟲時,它會不確定要為搜索查詢索引哪些具備良好競爭力優質的頁面。
URL帶參數不好看,也很難閱讀,看起來不那么值得用戶信任。因此,它們被點擊的可能性較小。點擊率可以影響排名,及FeedBack頁面的質量。它在社交媒體、電子郵件、復制粘貼到論壇或其他任何可能顯示完整 URL 的地方時,其點擊率都較低。
雖然這可能只會對單個頁面的產生一些影響,但每條推文、點贊、分享、電子郵件、鏈接和提及對整體域名而言都很重要。另外,URL 可讀性差可能會導致品牌的參與度下降。
了解你網站上使用的每個參數非常重要(也可以問開發人員)。
那么如何找到網站上所有需要處理的參數呢?介紹幾個方法:
1、運行爬蟲:使用 Screaming Frog 之類的工具,你可以搜索“?” 在網址中
2、查看你的日志文件:查看 Googlebot 是否在抓取基于參數的網址
3、使用站點搜索:inurl:高級運算符:通過將鍵放入 site:example.com inurl:key 組合查詢,了解 Google 如何為你找到的參數編制索引
4、查看 Google Analytics(分析)所有頁面報告:搜索“?” 查看你找到的每個參數是如何被用戶使用的。請務必檢查是否未在視圖設置中排除 URL 查詢參數
5、查看 Google Search Console URL 參數工具(現已廢棄):Google 會自動添加它找到的查詢字符串
有了這些數據,你現在可以決定如何最好地處理你網站的每個參數。
對源頭進行思考處理,找到減少參數 URL 數量的方法,從而最大限度地減少負面 SEO 影響。有四個常見思路:
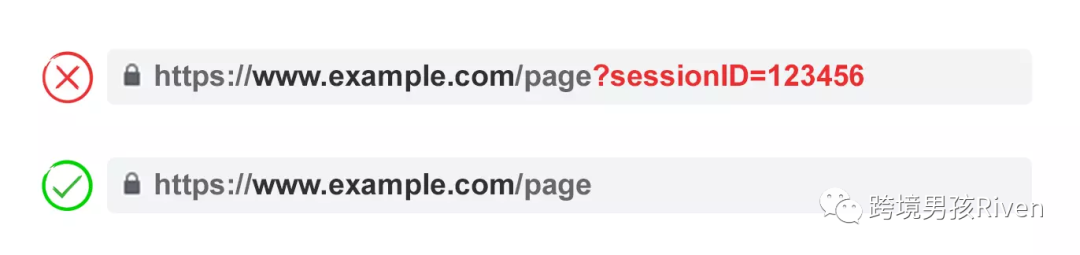
1) 去掉不必要的參數
圖片來源:Google
向你的開發人員索取每個網站參數及其功能的列表。你可能會發現一些沒有價值功能的參數。(例如,cookie可以比 sessionID 更好地識別用戶,然而 sessionID 參數可能仍然存在于你的網站上,之前使用過。)
或者你可能會發現你的用戶很少應用分頁導航中的過濾器。任何由技術問題引起的參數都應該早點優化處理。
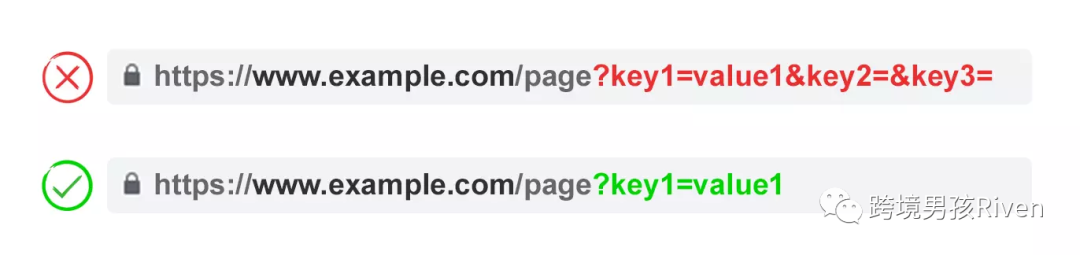
2) 防止空值(Value)
圖片來源:Google
只有當 URL 參數具有功能時,才應將 URL 參數添加到 URL。如果值為空,則不允許添加參數鍵。在上面的示例中,key2 和 key3 都沒有添加任何值。
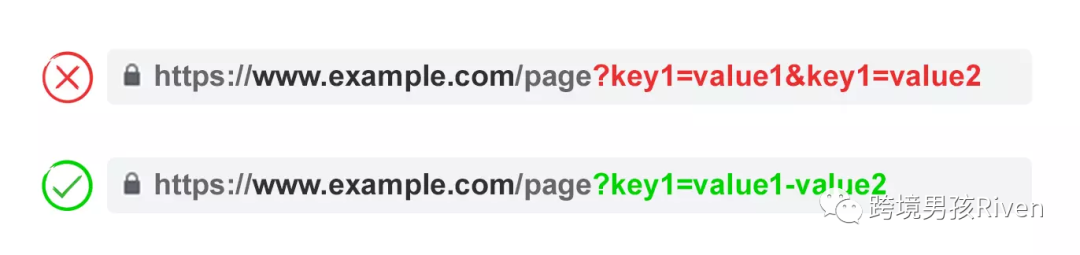
3) 只使用一次密鑰(Key)
圖片來源:Google
避免應用具有相同參數名稱和不同值的多個參數。對于多選選項,最好在單個鍵之后將值組合在一起。
4) 網址參數順序一致
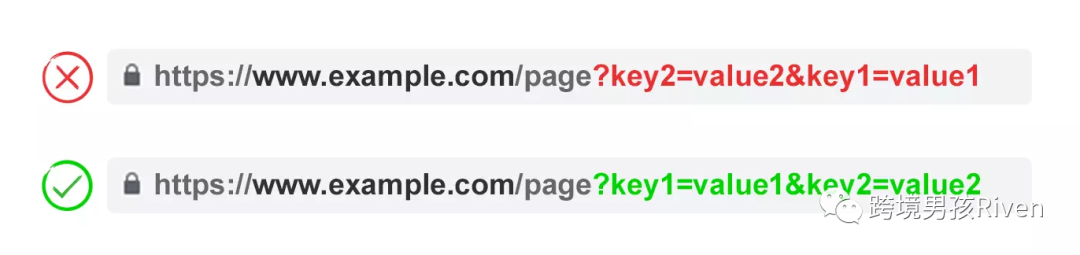
圖片來源:Google
如果重新排列相同的 URL 參數,則搜索引擎會將頁面解釋為相同的。
因此,從重復內容的角度來看,參數順序并不重要。但是這些組合中的每一個都會消耗抓取預算和拆分排名信號。
通過要求你的開發人員編寫腳本以始終以一致的順序放置參數來避免這些問題,而不管用戶如何選擇它們。
在我看來,你應該從任何翻譯參數開始、然后是識別、然后是分頁、然后是過濾和重新排序或搜索參數的分層,最后是跟蹤。
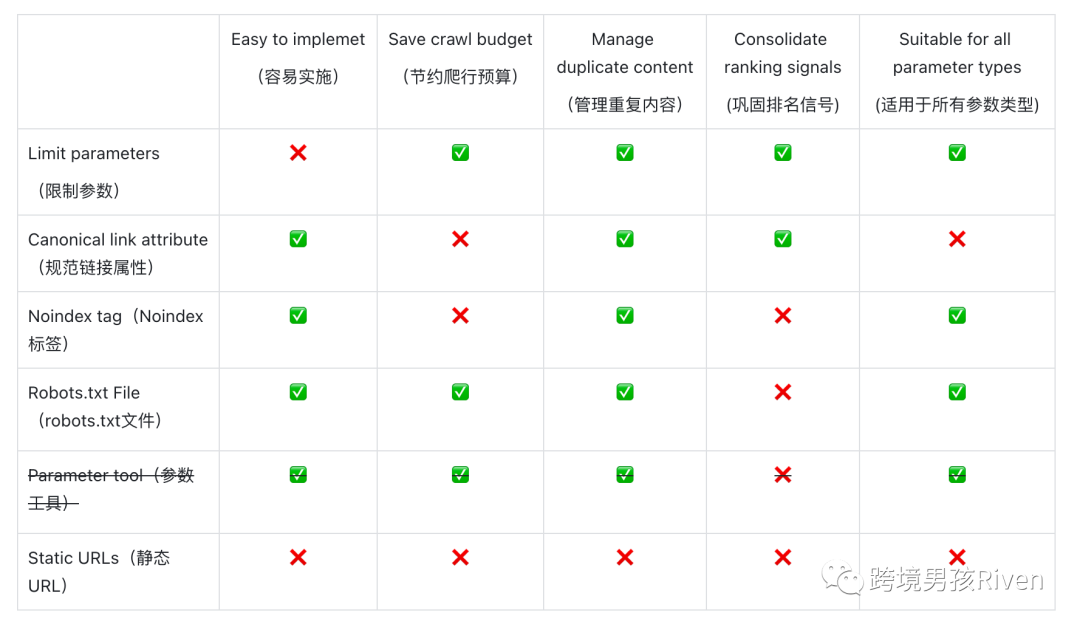
優點:
-減少重復內容問題
-將排名信號合并到更少的頁面
-適用于所有參數類型
缺點:
rel="canonical" 鏈接屬性表明一個頁面與另一個頁面具有相同或相似的內容。這鼓勵搜索引擎將排名信號整合到指定為規范的 URL。
你可以將基于參數的 URL rel="canonical" 到你的 SEO 友好 URL,比如跟蹤、識別或重新排序參數。但這種策略不適用于參數頁面內容與規范不夠接近的情況,例如分頁、搜索、翻譯或一些過濾參數。
優點:
缺點:
為任何不添加 SEO 價值的基于參數的頁面設置 noindex 指令。此標簽將阻止搜索引擎將該頁面編入索引。
帶有"noindex"標簽的 URL 也可能被不那么頻繁地抓取,如果它存在很長時間,最終會導致 Google 不關注該頁面的鏈接。
優點:
缺點:
User-agent: *
Disallow: /collections/*sort_by*
Disallow: /*/collections/*sort_by*
Disallow: /collections/*+*
Disallow: /collections/*%2B*
Disallow: /collections/*%2b*
Disallow: /*/collections/*+*
Disallow: /*/collections/*%2B*
Disallow: /*/collections/*%2b*
Disallow: /blogs/*+*
Disallow: /blogs/*%2B*
Disallow: /blogs/*%2b*
Disallow: /*/blogs/*+*
Disallow: /*/blogs/*%2B*
Disallow: /*/blogs/*%2b*
Disallow: /*?*oseid=*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
Disallow: /*/*?*ls=*&ls=*
Disallow: /*/*?*ls%3D*%3Fls%3D*
Disallow: /*/*?*ls%3d*%3fls%3d*
Disallow: /search
# Google adsbot ignores robots.txt unless specifically named!
User-agent: adsbot-google
Disallow: /*?*oseid=*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
robots.txt 文件是搜索引擎在抓取你的網站之前首先查看的文件。如果他們看到某些東西是不允許的,他們就不會去采集收錄。
你可以使用此文件阻止爬蟲訪問每個基于參數的 URL(使用 Disallow: /*?*)或僅阻止你不想被索引的特定查詢字符串。
如果你選擇使用Shopify或Shopline建站,則這些都已經被很好的處理了,商家不用處理。
優點:
缺點:
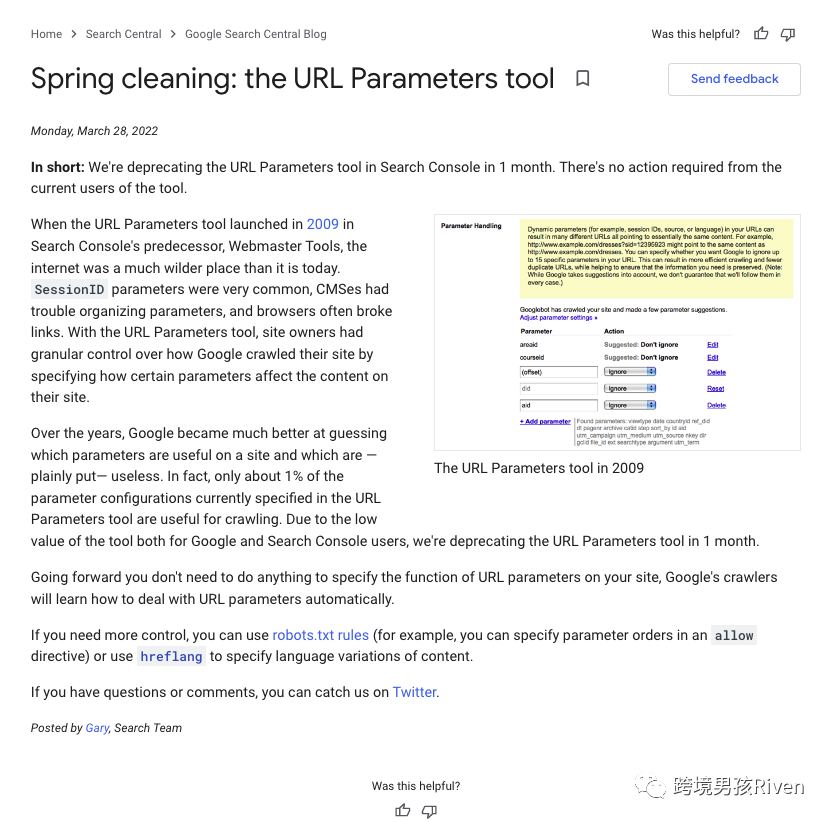
圖片來源:Google
在2022年3月以前是支持配置 Google 的 URL 參數工具,告訴抓取工具你的參數的用途以及你希望如何處理它們。
但Google2022年3月發布的更新中,指出:
多年來,谷歌在猜測網站上哪些參數有用,哪些參數——簡單地說——無用方面變得更好了。事實上,目前在 URL Parameters 工具中指定的參數配置中只有大約 1% 對爬取有用。由于該工具對 Google 和 Search Console 用戶的價值較低,我們將在 1 個月內棄用 URL 參數工具。今后,你無需在網站上指定 URL 參數的功能,Google 的爬蟲將學習如何自動處理 URL 參數。
很多人認為處理 URL 參數的最佳方法是首先避免使用它們。畢竟,子文件夾形式比參數更好來幫助谷歌理解網站結構。靜態的基于關鍵字的 URL 一直是頁面 SEO 基本標準。
為此,你可以使用服務器端 URL 重寫將參數轉換為子文件夾 URL。
例如,網址:
www.example.com/view-product?id=482794
會處理為:
www.example.com/widgets/blue
這種方法適用于描述性的基于關鍵字的參數,例如識別類別、產品或過濾搜索引擎相關屬性的參數,對于翻譯的版本內容也可以。
但是對于分面導航的非關鍵字相關元素(例如價格)來說,就會出現問題。擁有像靜態、可索引 URL 這樣的過濾器沒有提供 SEO 價值。
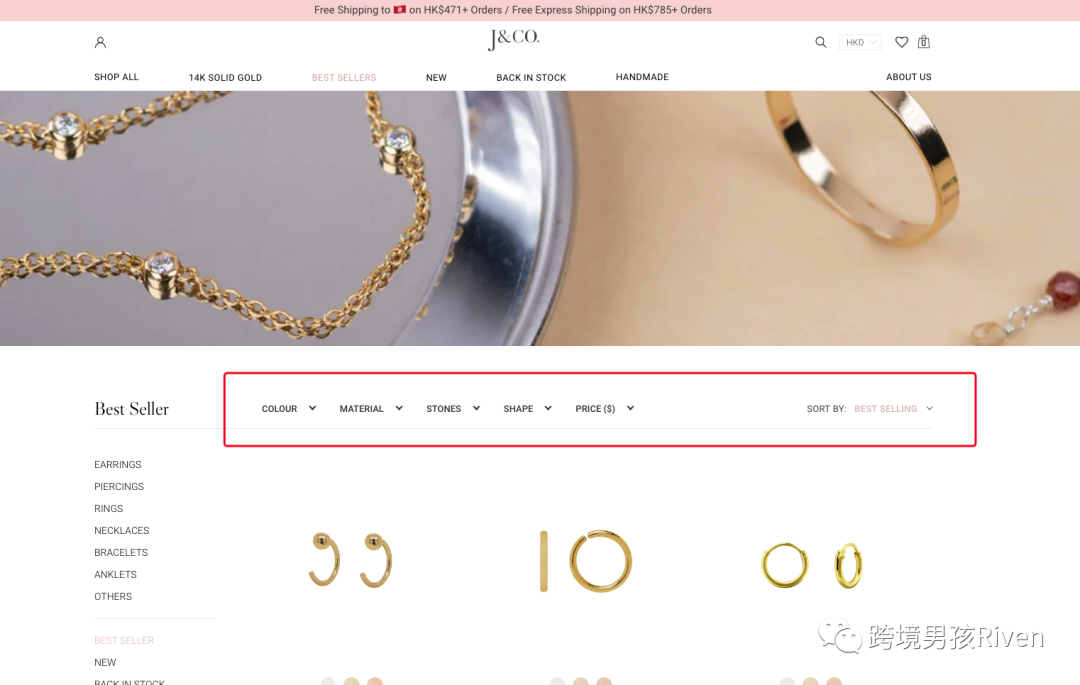
圖片來源:J&CO獨立站
這也是搜索參數的一個問題,因為每個用戶生成的查詢都會創建一個靜態頁面,會與規范的頁面爭奪排名。更糟糕的是,每當用戶搜索你不提供的頁面時,就會向爬蟲呈現低質量的內容頁面。(實際上Shopify及Shopline很好的將search url進行disallow處理了)
應用于分頁時有點奇怪(盡管WordPress 并不少見),它會給出一個 URL,例如:
www.example.com/widgets/blue/page2
URL靜態化后會非常奇怪,將給出一個 URL,例如:
www.example.com/widgets/blue/lowest-price
所以對于你不希望在搜索結果中被索引的參數(分頁、重新排序、跟蹤等),將其作為查詢字符串實現。對于你確實要編入索引的參數,就可以使用靜態 URL 路徑。
優點:
缺點:
那么應該實施哪種 SEO 策略中的哪一種呢?并不可能是全部策略都采用。全部采用會變得更復雜或者相互沖突。(例如,如果你實施 robots.txt 禁止,Google 將無法看到任何meta noindex 標記;也不應該將 meta noindex 標記與 rel=canonical鏈接屬性結合使用。)
圖片來源:Quara問答
其實,沒有一個完美的解決方案。在某些情況下,爬行效率比鞏固權威信號更重要。
最后,你網站選擇什么樣的方式將取決于你的優先級。
圖片來源:Riven@跨境男孩
總結,對于 SEO 友好的參數處理建議 :
1)進行關鍵字研究來了解哪些參數應該是搜索引擎友好的靜態 URL
2)使用rel="next" & rel="prev"實現正確的分頁處理
3)通過去掉不必要的參數來縮短 URL,同時對于所有剩余的基于參數的 URL,實施一致的排序規則,該規則僅使用一次鍵(Key)并防止空值(Value)以限制 URL 的數量
4)將 rel="canonical" 鏈接屬性添加到合適的參數頁面,以將排名信號整合到規范頁面
5)仔細檢查 XML 站點地圖中是否提交了基于參數的 URL
6)考慮使用 robots.txt 文件來阻止 Googlebot 訪問有問題的網址。通常,考慮阻止動態 URL,例如生成搜索結果的 URL,或可以創建無限空間的 URL,例如日歷。在 robots.txt 文件中使用正則表達式可以讓你輕松阻止大量 URL
7)盡可能避免在 URL 中使用會話 ID,考慮改用 cookie
8)如果你的站點有無限日歷,為鏈接添加一個"nofollow"屬性
(來源:跨境男孩)
以上內容屬作者個人觀點,不代表雨果跨境立場!本文經原作者授權轉載,轉載需經原作者授權同意。?
 收錄于以下專欄
收錄于以下專欄
































